Supervised Learning with scikit-learn
Contents
18. Supervised Learning with scikit-learn¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import sklearn
from sklearn import datasets
18.1. Classification¶
18.1.1. KNN (binary)¶
18.1.1.1. 讀資料集¶
vote_raw = pd.read_csv("data/house-votes-84.csv")
vote = vote_raw.copy()
col_names = ['party', 'infants', 'water', 'budget', 'physician', 'salvador',
'religious', 'satellite', 'aid', 'missile', 'immigration', 'synfuels',
'education', 'superfund', 'crime', 'duty_free_exports', 'eaa_rsa']
vote.columns = col_names
vote[vote == "?"] = np.nan # 把 ? 改成 na
vote = vote.dropna()
for i in col_names[1:]:
vote[i] = vote[i].replace({"y": 1, "n": 0})
vote
| party | infants | water | budget | physician | salvador | religious | satellite | aid | missile | immigration | synfuels | education | superfund | crime | duty_free_exports | eaa_rsa | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | democrat | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 7 | republican | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| 18 | democrat | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| 22 | democrat | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 24 | democrat | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 422 | democrat | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| 425 | democrat | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 426 | republican | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| 429 | republican | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| 430 | democrat | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
232 rows × 17 columns
vote.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 232 entries, 4 to 430
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 party 232 non-null object
1 infants 232 non-null int64
2 water 232 non-null int64
3 budget 232 non-null int64
4 physician 232 non-null int64
5 salvador 232 non-null int64
6 religious 232 non-null int64
7 satellite 232 non-null int64
8 aid 232 non-null int64
9 missile 232 non-null int64
10 immigration 232 non-null int64
11 synfuels 232 non-null int64
12 education 232 non-null int64
13 superfund 232 non-null int64
14 crime 232 non-null int64
15 duty_free_exports 232 non-null int64
16 eaa_rsa 232 non-null int64
dtypes: int64(16), object(1)
memory usage: 32.6+ KB
這筆資料共 232 個列,每一列是一個立委
y 是 party(該立委所屬的政黨,民主黨或共和黨)
剩下的全都是x,這些x都是各大議題的投票結果。以
infants這個變數來說,就是在嬰兒這個議題上,此立委是投贊成票(1)還是反對票(0).那這筆資料的任務,就是根據這些議題的投票結果,來猜這個立委屬於哪個政黨
18.1.1.2. 最簡單流程¶
先來講最簡單的流程
分 train/test
~~定 pipeline.~~
~~定義 preprocessing steps.~~
定義 classifier.
~~hyper-parameter tunning~~
~~grid search~~
~~random search~~
用整個 training set 做 fitting.
對 testing set 做 predict.
評估模型表現
threshold.
non-trheshold
細節資訊探索(e.g. fitting後的參數,…)
18.1.1.2.1. 分 train/test¶
# 分 train/test
X = vote.drop("party", axis = 1)
y = vote["party"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = 0.3,
random_state = 21,
stratify = y
)
可以看看,X_train 和 X_test 的資料筆數分配
print(f"The shape of X_train is: {X_train.shape}")
print(f"The shape of X_test is: {X_test.shape}")
The shape of X_train is: (162, 16)
The shape of X_test is: (70, 16)
可以看, y_train 和 y_test 的分佈是不是一樣(因為我有做 stratify)
print(f"republican% in whole data set is: {(y == 'republican').sum()/y.size}")
print(f"republican% in training set is: {(y_train == 'republican').sum()/y_train.size}")
print(f"republican% in testing set is: {(y_test == 'republican').sum()/y_test.size}")
republican% in whole data set is: 0.46551724137931033
republican% in training set is: 0.46296296296296297
republican% in testing set is: 0.4714285714285714
18.1.1.2.2. 做 pipeline¶
pipeline 包括 preprocessing + model,那這邊只做 model
# 定 pipeline
## 定 preprocessing steps. (略)
## 定 classifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5)
很簡單的就定義完我要使用的 model (knn,以及 neighbor 數選了 5).
我們可以看他的文件,來看這個 classifier 的細節
KNeighborsClassifier?
Init signature:
KNeighborsClassifier(
n_neighbors=5,
*,
weights='uniform',
algorithm='auto',
leaf_size=30,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=None,
)
Docstring:
Classifier implementing the k-nearest neighbors vote.
Read more in the :ref:`User Guide <classification>`.
Parameters
----------
n_neighbors : int, default=5
Number of neighbors to use by default for :meth:`kneighbors` queries.
weights : {'uniform', 'distance'} or callable, default='uniform'
Weight function used in prediction. Possible values:
- 'uniform' : uniform weights. All points in each neighborhood
are weighted equally.
- 'distance' : weight points by the inverse of their distance.
in this case, closer neighbors of a query point will have a
greater influence than neighbors which are further away.
- [callable] : a user-defined function which accepts an
array of distances, and returns an array of the same shape
containing the weights.
algorithm : {'auto', 'ball_tree', 'kd_tree', 'brute'}, default='auto'
Algorithm used to compute the nearest neighbors:
- 'ball_tree' will use :class:`BallTree`
- 'kd_tree' will use :class:`KDTree`
- 'brute' will use a brute-force search.
- 'auto' will attempt to decide the most appropriate algorithm
based on the values passed to :meth:`fit` method.
Note: fitting on sparse input will override the setting of
this parameter, using brute force.
leaf_size : int, default=30
Leaf size passed to BallTree or KDTree. This can affect the
speed of the construction and query, as well as the memory
required to store the tree. The optimal value depends on the
nature of the problem.
p : int, default=2
Power parameter for the Minkowski metric. When p = 1, this is
equivalent to using manhattan_distance (l1), and euclidean_distance
(l2) for p = 2. For arbitrary p, minkowski_distance (l_p) is used.
metric : str or callable, default='minkowski'
The distance metric to use for the tree. The default metric is
minkowski, and with p=2 is equivalent to the standard Euclidean
metric. For a list of available metrics, see the documentation of
:class:`~sklearn.metrics.DistanceMetric`.
If metric is "precomputed", X is assumed to be a distance matrix and
must be square during fit. X may be a :term:`sparse graph`,
in which case only "nonzero" elements may be considered neighbors.
metric_params : dict, default=None
Additional keyword arguments for the metric function.
n_jobs : int, default=None
The number of parallel jobs to run for neighbors search.
``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
``-1`` means using all processors. See :term:`Glossary <n_jobs>`
for more details.
Doesn't affect :meth:`fit` method.
Attributes
----------
classes_ : array of shape (n_classes,)
Class labels known to the classifier
effective_metric_ : str or callble
The distance metric used. It will be same as the `metric` parameter
or a synonym of it, e.g. 'euclidean' if the `metric` parameter set to
'minkowski' and `p` parameter set to 2.
effective_metric_params_ : dict
Additional keyword arguments for the metric function. For most metrics
will be same with `metric_params` parameter, but may also contain the
`p` parameter value if the `effective_metric_` attribute is set to
'minkowski'.
n_features_in_ : int
Number of features seen during :term:`fit`.
.. versionadded:: 0.24
feature_names_in_ : ndarray of shape (`n_features_in_`,)
Names of features seen during :term:`fit`. Defined only when `X`
has feature names that are all strings.
.. versionadded:: 1.0
n_samples_fit_ : int
Number of samples in the fitted data.
outputs_2d_ : bool
False when `y`'s shape is (n_samples, ) or (n_samples, 1) during fit
otherwise True.
See Also
--------
RadiusNeighborsClassifier: Classifier based on neighbors within a fixed radius.
KNeighborsRegressor: Regression based on k-nearest neighbors.
RadiusNeighborsRegressor: Regression based on neighbors within a fixed radius.
NearestNeighbors: Unsupervised learner for implementing neighbor searches.
Notes
-----
See :ref:`Nearest Neighbors <neighbors>` in the online documentation
for a discussion of the choice of ``algorithm`` and ``leaf_size``.
.. warning::
Regarding the Nearest Neighbors algorithms, if it is found that two
neighbors, neighbor `k+1` and `k`, have identical distances
but different labels, the results will depend on the ordering of the
training data.
https://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
Examples
--------
>>> X = [[0], [1], [2], [3]]
>>> y = [0, 0, 1, 1]
>>> from sklearn.neighbors import KNeighborsClassifier
>>> neigh = KNeighborsClassifier(n_neighbors=3)
>>> neigh.fit(X, y)
KNeighborsClassifier(...)
>>> print(neigh.predict([[1.1]]))
[0]
>>> print(neigh.predict_proba([[0.9]]))
[[0.666... 0.333...]]
File: /Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/neighbors/_classification.py
Type: ABCMeta
Subclasses:
18.1.1.2.3. 用整個 training set 做 fitting.¶
knn.fit(X_train, y_train)
KNeighborsClassifier()
fitting 完後,可以簡要看一下他學到了啥
knn.effective_metric_
'euclidean'
18.1.1.2.4. 對 testing set 做 predict¶
y_pred = knn.predict(X_test)
y_pred_prob = knn.predict_proba(X_test)
我們看看預測結果(label)
pd.DataFrame(y_pred, columns= ["pred_label"]).head()
| pred_label | |
|---|---|
| 0 | democrat |
| 1 | democrat |
| 2 | republican |
| 3 | democrat |
| 4 | republican |
這個預測值,就是去比預測此委員為 democrat 的機率,和 republican 的機率,哪個大,而做出的判斷. (因為只有兩類,所以其實就是 threshold = 0.5 -> 如果 republican 的機率值 > 0.5,就判定為 republican (y的positive是republican)
所以我們來看一下預測機率值
pd.DataFrame(y_pred_prob, columns= y_test.unique()).head()
| democrat | republican | |
|---|---|---|
| 0 | 1.0 | 0.0 |
| 1 | 1.0 | 0.0 |
| 2 | 0.0 | 1.0 |
| 3 | 1.0 | 0.0 |
| 4 | 0.0 | 1.0 |
這個機率的算法,就是找最近的 k 個 neighbor後,去統計 democrat 的比例,和 republican 的比例.
所以以 index = 0 這一列來說,就是離此委員最近的 k 個 neighbor,全都是 democrat。
18.1.1.2.5. 效果評估¶
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score
# 評估結果
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
[[32 5]
[ 2 31]]
precision recall f1-score support
democrat 0.94 0.86 0.90 37
republican 0.86 0.94 0.90 33
accuracy 0.90 70
macro avg 0.90 0.90 0.90 70
weighted avg 0.90 0.90 0.90 70
可以看到,如果你把
republican當 positive 的話,就看第二列precision: 0.86,表示你預測他是republican的人中,有86%真的是republican.
recall: 0.94,表示實際上是republican的人中,有94%被你抓到.
f1-score: 是precision和recall的調和平均數.
接著看 index =
accuracy那一列,可以看到,準確率是 0.90.
y_pred_prob
array([[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0.4, 0.6],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0.8, 0.2],
[1. , 0. ],
[0.4, 0.6],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0.8, 0.2],
[0. , 1. ],
[0. , 1. ],
[0.2, 0.8],
[0.8, 0.2],
[0. , 1. ],
[1. , 0. ],
[0.4, 0.6],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ]])
y_test_trans = (y_test=="republican") # republican = 1, democrat = 0
y_pred_prob_trans = y_pred_prob[:,1] # 預測是 republican 的 機率
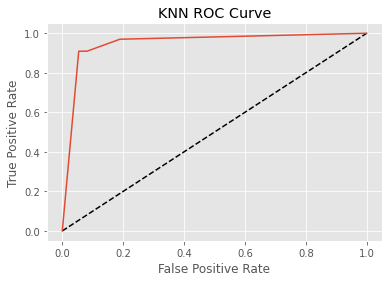
auc = roc_auc_score(y_test_trans, y_pred_prob_trans)
print(f"auc: {auc}")
fpr, tpr, thresholds = roc_curve(y_test_trans, y_pred_prob_trans)
plt.plot([0,1],[0, 1], "k--")
plt.plot(fpr, tpr, label = "KNN (K = 5)")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("KNN ROC Curve")
plt.show()
auc: 0.9492219492219492
18.1.1.3. 最完整流程整理¶
來講最完整的流程
分 train/test
定 pipeline
定義 preprocessing steps
定義 classifier.
hyper-parameter tunning
grid search
random search
用整個 training set 做 fitting.
對 testing set 做 predict.
評估模型表現
threshold.
non-trheshold
細節資訊探索(e.g. fitting後的參數,…)
18.1.1.3.1. 分 train/test¶
# 分 train/test
X = vote.drop("party", axis = 1)
y = vote["party"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = 0.3,
random_state = 21,
stratify = y
)
18.1.1.3.2. 做 pipeline¶
對 knn 這種依賴 euclidean distance 的演算法,必須先做 normalization,再開始算距離,所以 pipeline寫成這樣:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# preprocess
scaler = StandardScaler()
# model
knn = KNeighborsClassifier()
# pipeline
my_pipe = Pipeline([
("scaler", scaler),
("knn", knn)
])
18.1.1.3.3. 做 hyper-parameter tunning¶
先來做 grid_search
from sklearn.model_selection import GridSearchCV
parameters = {"knn__n_neighbors": np.arange(1, 50)}
grid_cv = GridSearchCV(my_pipe,
param_grid = parameters,
cv = 5,
scoring='roc_auc');
grid_cv.fit(X_train, y_train);
這邊看一下,第二列的 parameters 裡面,”knn__”的knn,是用我的 my_pipe 物件裡的名稱 (“knn”); “n_neighbors” 是超參數的名稱
做完 fitting 後的物件就是 grid_cv 了,我們可以看最佳參數是多少:
grid_cv.best_params_
{'knn__n_neighbors': 17}
可以知道,最佳參數是 17.
?ref:scoring_parameter
Object `ref:scoring_parameter` not found.
?GridSearchCV
Init signature:
GridSearchCV(
estimator,
param_grid,
*,
scoring=None,
n_jobs=None,
refit=True,
cv=None,
verbose=0,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False,
)
Docstring:
Exhaustive search over specified parameter values for an estimator.
Important members are fit, predict.
GridSearchCV implements a "fit" and a "score" method.
It also implements "score_samples", "predict", "predict_proba",
"decision_function", "transform" and "inverse_transform" if they are
implemented in the estimator used.
The parameters of the estimator used to apply these methods are optimized
by cross-validated grid-search over a parameter grid.
Read more in the :ref:`User Guide <grid_search>`.
Parameters
----------
estimator : estimator object
This is assumed to implement the scikit-learn estimator interface.
Either estimator needs to provide a ``score`` function,
or ``scoring`` must be passed.
param_grid : dict or list of dictionaries
Dictionary with parameters names (`str`) as keys and lists of
parameter settings to try as values, or a list of such
dictionaries, in which case the grids spanned by each dictionary
in the list are explored. This enables searching over any sequence
of parameter settings.
scoring : str, callable, list, tuple or dict, default=None
Strategy to evaluate the performance of the cross-validated model on
the test set.
If `scoring` represents a single score, one can use:
- a single string (see :ref:`scoring_parameter`);
- a callable (see :ref:`scoring`) that returns a single value.
If `scoring` represents multiple scores, one can use:
- a list or tuple of unique strings;
- a callable returning a dictionary where the keys are the metric
names and the values are the metric scores;
- a dictionary with metric names as keys and callables a values.
See :ref:`multimetric_grid_search` for an example.
n_jobs : int, default=None
Number of jobs to run in parallel.
``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
``-1`` means using all processors. See :term:`Glossary <n_jobs>`
for more details.
.. versionchanged:: v0.20
`n_jobs` default changed from 1 to None
refit : bool, str, or callable, default=True
Refit an estimator using the best found parameters on the whole
dataset.
For multiple metric evaluation, this needs to be a `str` denoting the
scorer that would be used to find the best parameters for refitting
the estimator at the end.
Where there are considerations other than maximum score in
choosing a best estimator, ``refit`` can be set to a function which
returns the selected ``best_index_`` given ``cv_results_``. In that
case, the ``best_estimator_`` and ``best_params_`` will be set
according to the returned ``best_index_`` while the ``best_score_``
attribute will not be available.
The refitted estimator is made available at the ``best_estimator_``
attribute and permits using ``predict`` directly on this
``GridSearchCV`` instance.
Also for multiple metric evaluation, the attributes ``best_index_``,
``best_score_`` and ``best_params_`` will only be available if
``refit`` is set and all of them will be determined w.r.t this specific
scorer.
See ``scoring`` parameter to know more about multiple metric
evaluation.
.. versionchanged:: 0.20
Support for callable added.
cv : int, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy.
Possible inputs for cv are:
- None, to use the default 5-fold cross validation,
- integer, to specify the number of folds in a `(Stratified)KFold`,
- :term:`CV splitter`,
- An iterable yielding (train, test) splits as arrays of indices.
For integer/None inputs, if the estimator is a classifier and ``y`` is
either binary or multiclass, :class:`StratifiedKFold` is used. In all
other cases, :class:`KFold` is used. These splitters are instantiated
with `shuffle=False` so the splits will be the same across calls.
Refer :ref:`User Guide <cross_validation>` for the various
cross-validation strategies that can be used here.
.. versionchanged:: 0.22
``cv`` default value if None changed from 3-fold to 5-fold.
verbose : int
Controls the verbosity: the higher, the more messages.
- >1 : the computation time for each fold and parameter candidate is
displayed;
- >2 : the score is also displayed;
- >3 : the fold and candidate parameter indexes are also displayed
together with the starting time of the computation.
pre_dispatch : int, or str, default='2*n_jobs'
Controls the number of jobs that get dispatched during parallel
execution. Reducing this number can be useful to avoid an
explosion of memory consumption when more jobs get dispatched
than CPUs can process. This parameter can be:
- None, in which case all the jobs are immediately
created and spawned. Use this for lightweight and
fast-running jobs, to avoid delays due to on-demand
spawning of the jobs
- An int, giving the exact number of total jobs that are
spawned
- A str, giving an expression as a function of n_jobs,
as in '2*n_jobs'
error_score : 'raise' or numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting.
If set to 'raise', the error is raised. If a numeric value is given,
FitFailedWarning is raised. This parameter does not affect the refit
step, which will always raise the error.
return_train_score : bool, default=False
If ``False``, the ``cv_results_`` attribute will not include training
scores.
Computing training scores is used to get insights on how different
parameter settings impact the overfitting/underfitting trade-off.
However computing the scores on the training set can be computationally
expensive and is not strictly required to select the parameters that
yield the best generalization performance.
.. versionadded:: 0.19
.. versionchanged:: 0.21
Default value was changed from ``True`` to ``False``
Attributes
----------
cv_results_ : dict of numpy (masked) ndarrays
A dict with keys as column headers and values as columns, that can be
imported into a pandas ``DataFrame``.
For instance the below given table
+------------+-----------+------------+-----------------+---+---------+
|param_kernel|param_gamma|param_degree|split0_test_score|...|rank_t...|
+============+===========+============+=================+===+=========+
| 'poly' | -- | 2 | 0.80 |...| 2 |
+------------+-----------+------------+-----------------+---+---------+
| 'poly' | -- | 3 | 0.70 |...| 4 |
+------------+-----------+------------+-----------------+---+---------+
| 'rbf' | 0.1 | -- | 0.80 |...| 3 |
+------------+-----------+------------+-----------------+---+---------+
| 'rbf' | 0.2 | -- | 0.93 |...| 1 |
+------------+-----------+------------+-----------------+---+---------+
will be represented by a ``cv_results_`` dict of::
{
'param_kernel': masked_array(data = ['poly', 'poly', 'rbf', 'rbf'],
mask = [False False False False]...)
'param_gamma': masked_array(data = [-- -- 0.1 0.2],
mask = [ True True False False]...),
'param_degree': masked_array(data = [2.0 3.0 -- --],
mask = [False False True True]...),
'split0_test_score' : [0.80, 0.70, 0.80, 0.93],
'split1_test_score' : [0.82, 0.50, 0.70, 0.78],
'mean_test_score' : [0.81, 0.60, 0.75, 0.85],
'std_test_score' : [0.01, 0.10, 0.05, 0.08],
'rank_test_score' : [2, 4, 3, 1],
'split0_train_score' : [0.80, 0.92, 0.70, 0.93],
'split1_train_score' : [0.82, 0.55, 0.70, 0.87],
'mean_train_score' : [0.81, 0.74, 0.70, 0.90],
'std_train_score' : [0.01, 0.19, 0.00, 0.03],
'mean_fit_time' : [0.73, 0.63, 0.43, 0.49],
'std_fit_time' : [0.01, 0.02, 0.01, 0.01],
'mean_score_time' : [0.01, 0.06, 0.04, 0.04],
'std_score_time' : [0.00, 0.00, 0.00, 0.01],
'params' : [{'kernel': 'poly', 'degree': 2}, ...],
}
NOTE
The key ``'params'`` is used to store a list of parameter
settings dicts for all the parameter candidates.
The ``mean_fit_time``, ``std_fit_time``, ``mean_score_time`` and
``std_score_time`` are all in seconds.
For multi-metric evaluation, the scores for all the scorers are
available in the ``cv_results_`` dict at the keys ending with that
scorer's name (``'_<scorer_name>'``) instead of ``'_score'`` shown
above. ('split0_test_precision', 'mean_train_precision' etc.)
best_estimator_ : estimator
Estimator that was chosen by the search, i.e. estimator
which gave highest score (or smallest loss if specified)
on the left out data. Not available if ``refit=False``.
See ``refit`` parameter for more information on allowed values.
best_score_ : float
Mean cross-validated score of the best_estimator
For multi-metric evaluation, this is present only if ``refit`` is
specified.
This attribute is not available if ``refit`` is a function.
best_params_ : dict
Parameter setting that gave the best results on the hold out data.
For multi-metric evaluation, this is present only if ``refit`` is
specified.
best_index_ : int
The index (of the ``cv_results_`` arrays) which corresponds to the best
candidate parameter setting.
The dict at ``search.cv_results_['params'][search.best_index_]`` gives
the parameter setting for the best model, that gives the highest
mean score (``search.best_score_``).
For multi-metric evaluation, this is present only if ``refit`` is
specified.
scorer_ : function or a dict
Scorer function used on the held out data to choose the best
parameters for the model.
For multi-metric evaluation, this attribute holds the validated
``scoring`` dict which maps the scorer key to the scorer callable.
n_splits_ : int
The number of cross-validation splits (folds/iterations).
refit_time_ : float
Seconds used for refitting the best model on the whole dataset.
This is present only if ``refit`` is not False.
.. versionadded:: 0.20
multimetric_ : bool
Whether or not the scorers compute several metrics.
classes_ : ndarray of shape (n_classes,)
The classes labels. This is present only if ``refit`` is specified and
the underlying estimator is a classifier.
n_features_in_ : int
Number of features seen during :term:`fit`. Only defined if
`best_estimator_` is defined (see the documentation for the `refit`
parameter for more details) and that `best_estimator_` exposes
`n_features_in_` when fit.
.. versionadded:: 0.24
feature_names_in_ : ndarray of shape (`n_features_in_`,)
Names of features seen during :term:`fit`. Only defined if
`best_estimator_` is defined (see the documentation for the `refit`
parameter for more details) and that `best_estimator_` exposes
`feature_names_in_` when fit.
.. versionadded:: 1.0
Notes
-----
The parameters selected are those that maximize the score of the left out
data, unless an explicit score is passed in which case it is used instead.
If `n_jobs` was set to a value higher than one, the data is copied for each
point in the grid (and not `n_jobs` times). This is done for efficiency
reasons if individual jobs take very little time, but may raise errors if
the dataset is large and not enough memory is available. A workaround in
this case is to set `pre_dispatch`. Then, the memory is copied only
`pre_dispatch` many times. A reasonable value for `pre_dispatch` is `2 *
n_jobs`.
See Also
---------
ParameterGrid : Generates all the combinations of a hyperparameter grid.
train_test_split : Utility function to split the data into a development
set usable for fitting a GridSearchCV instance and an evaluation set
for its final evaluation.
sklearn.metrics.make_scorer : Make a scorer from a performance metric or
loss function.
Examples
--------
>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import GridSearchCV
>>> iris = datasets.load_iris()
>>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
>>> svc = svm.SVC()
>>> clf = GridSearchCV(svc, parameters)
>>> clf.fit(iris.data, iris.target)
GridSearchCV(estimator=SVC(),
param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')})
>>> sorted(clf.cv_results_.keys())
['mean_fit_time', 'mean_score_time', 'mean_test_score',...
'param_C', 'param_kernel', 'params',...
'rank_test_score', 'split0_test_score',...
'split2_test_score', ...
'std_fit_time', 'std_score_time', 'std_test_score']
File: /Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/model_selection/_search.py
Type: ABCMeta
Subclasses:
grid_cv.cv_results_
{'mean_fit_time': array([0.00410557, 0.00349936, 0.00289578, 0.00251188, 0.00247269,
0.00252709, 0.00272069, 0.00246129, 0.00306287, 0.00371184,
0.00294638, 0.00308042, 0.00299649, 0.00300522, 0.00273948,
0.00361261, 0.00310259, 0.00313864, 0.00295277, 0.00384784,
0.00304828, 0.00281844, 0.00319686, 0.00302219, 0.00305853,
0.00290966, 0.00289521, 0.00281544, 0.00308471, 0.00267277,
0.00285001, 0.0030632 , 0.00333405, 0.00302234, 0.00311818,
0.00305524, 0.00284081, 0.00307274, 0.00295916, 0.00310979,
0.00310645, 0.00305629, 0.00277839, 0.00244412, 0.00253983,
0.00268669, 0.00238819, 0.00241308, 0.00232444]),
'std_fit_time': array([7.88619106e-04, 9.42372814e-04, 5.09592826e-04, 2.05940145e-04,
1.30329147e-04, 1.39555875e-04, 4.71658495e-04, 9.38250994e-05,
7.01362537e-04, 9.40648512e-04, 5.46725004e-04, 6.70972481e-04,
6.49284812e-04, 6.08038812e-04, 4.14937119e-04, 5.44774122e-04,
4.02125639e-04, 7.85894654e-04, 4.22827063e-04, 3.05221040e-04,
4.93310674e-04, 4.91984687e-04, 6.07253808e-04, 3.68679192e-04,
7.83753444e-04, 3.84013546e-04, 5.97170735e-04, 3.48093033e-04,
5.59792474e-04, 1.83740436e-04, 5.59706703e-04, 6.29626715e-04,
6.91515668e-04, 5.43012236e-04, 4.23518716e-04, 4.46913336e-04,
2.66436123e-04, 5.09237350e-04, 2.87175098e-04, 5.41384761e-04,
3.48689486e-04, 4.61566522e-04, 4.62282743e-05, 1.11534301e-04,
2.85003914e-04, 3.43765774e-04, 4.60957275e-05, 6.26801311e-05,
2.83467783e-04]),
'mean_score_time': array([0.0031558 , 0.00250463, 0.00250649, 0.00215402, 0.00216942,
0.00229611, 0.00228481, 0.00209074, 0.00282593, 0.00295038,
0.00259624, 0.00252881, 0.00267229, 0.00262327, 0.00244746,
0.00306764, 0.00275512, 0.00263891, 0.00269318, 0.00277519,
0.00260739, 0.00271072, 0.00273805, 0.0025115 , 0.00240846,
0.00260949, 0.00252876, 0.00271316, 0.00271668, 0.00248637,
0.00258036, 0.00288286, 0.0027564 , 0.00256944, 0.00278878,
0.00260425, 0.0026751 , 0.00264025, 0.00280237, 0.0027246 ,
0.00317144, 0.00274553, 0.00256987, 0.00226922, 0.00251756,
0.00245085, 0.0023438 , 0.00224037, 0.00238848]),
'std_score_time': array([1.11923762e-03, 5.02003516e-04, 6.28364240e-04, 2.53515694e-04,
1.18820261e-04, 2.69056802e-04, 2.76645180e-04, 7.58113199e-05,
6.51008842e-04, 6.12322828e-04, 5.13428608e-04, 4.03309776e-04,
4.90662646e-04, 4.82464803e-04, 2.78491622e-04, 2.98720787e-04,
3.83199448e-04, 4.57812113e-04, 3.96594125e-04, 4.14270047e-04,
4.59691211e-04, 4.23115014e-04, 3.26109745e-04, 2.89609198e-04,
2.27550939e-04, 4.39541240e-04, 3.07336423e-04, 6.50968867e-04,
3.49868736e-04, 1.77414479e-04, 2.67554022e-04, 4.83264888e-04,
4.17323549e-04, 2.95681527e-04, 2.24535524e-04, 3.38101453e-04,
2.95083632e-04, 3.19394449e-04, 4.91383988e-04, 3.39971364e-04,
5.14225423e-04, 4.11409220e-04, 9.38881830e-05, 3.99615144e-05,
2.96201578e-04, 2.11339188e-04, 8.54063938e-05, 6.91232000e-05,
3.91190910e-04]),
'param_knn__n_neighbors': masked_array(data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30,
31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44,
45, 46, 47, 48, 49],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False],
fill_value='?',
dtype=object),
'params': [{'knn__n_neighbors': 1},
{'knn__n_neighbors': 2},
{'knn__n_neighbors': 3},
{'knn__n_neighbors': 4},
{'knn__n_neighbors': 5},
{'knn__n_neighbors': 6},
{'knn__n_neighbors': 7},
{'knn__n_neighbors': 8},
{'knn__n_neighbors': 9},
{'knn__n_neighbors': 10},
{'knn__n_neighbors': 11},
{'knn__n_neighbors': 12},
{'knn__n_neighbors': 13},
{'knn__n_neighbors': 14},
{'knn__n_neighbors': 15},
{'knn__n_neighbors': 16},
{'knn__n_neighbors': 17},
{'knn__n_neighbors': 18},
{'knn__n_neighbors': 19},
{'knn__n_neighbors': 20},
{'knn__n_neighbors': 21},
{'knn__n_neighbors': 22},
{'knn__n_neighbors': 23},
{'knn__n_neighbors': 24},
{'knn__n_neighbors': 25},
{'knn__n_neighbors': 26},
{'knn__n_neighbors': 27},
{'knn__n_neighbors': 28},
{'knn__n_neighbors': 29},
{'knn__n_neighbors': 30},
{'knn__n_neighbors': 31},
{'knn__n_neighbors': 32},
{'knn__n_neighbors': 33},
{'knn__n_neighbors': 34},
{'knn__n_neighbors': 35},
{'knn__n_neighbors': 36},
{'knn__n_neighbors': 37},
{'knn__n_neighbors': 38},
{'knn__n_neighbors': 39},
{'knn__n_neighbors': 40},
{'knn__n_neighbors': 41},
{'knn__n_neighbors': 42},
{'knn__n_neighbors': 43},
{'knn__n_neighbors': 44},
{'knn__n_neighbors': 45},
{'knn__n_neighbors': 46},
{'knn__n_neighbors': 47},
{'knn__n_neighbors': 48},
{'knn__n_neighbors': 49}],
'split0_test_score': array([0.87222222, 0.91851852, 0.97222222, 0.96666667, 0.97407407,
0.97037037, 0.96481481, 0.97222222, 0.98148148, 0.98518519,
0.98148148, 0.97962963, 0.97777778, 0.97592593, 0.97222222,
0.96851852, 0.97407407, 0.97037037, 0.96666667, 0.97037037,
0.97777778, 0.97777778, 0.97777778, 0.97777778, 0.97777778,
0.98148148, 0.97777778, 0.97777778, 0.97777778, 0.97777778,
0.97777778, 0.97777778, 0.97592593, 0.97037037, 0.96851852,
0.96851852, 0.97592593, 0.97592593, 0.97592593, 0.97592593,
0.97407407, 0.97407407, 0.97407407, 0.97407407, 0.97407407,
0.97407407, 0.97407407, 0.97407407, 0.97777778]),
'split1_test_score': array([0.97222222, 0.97222222, 0.97222222, 0.97222222, 0.97222222,
1. , 1. , 0.99814815, 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
0.99814815, 0.99814815, 0.99814815, 0.99814815, 0.99814815,
0.99814815, 0.99814815, 0.9962963 , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
0.99814815, 0.99814815, 1. , 1. , 1. ,
1. , 1. , 1. , 1. ]),
'split2_test_score': array([0.93333333, 0.95882353, 0.95686275, 0.95686275, 0.95686275,
0.95294118, 0.95098039, 0.95098039, 0.94901961, 0.94705882,
0.95294118, 0.95294118, 0.98039216, 0.99019608, 0.99215686,
0.99019608, 0.98823529, 0.98823529, 0.98823529, 0.98627451,
0.98627451, 0.98431373, 0.98039216, 0.97647059, 0.9745098 ,
0.9745098 , 0.97254902, 0.97647059, 0.97647059, 0.98235294,
0.97843137, 0.97843137, 0.97843137, 0.97647059, 0.97647059,
0.9745098 , 0.9745098 , 0.97058824, 0.97058824, 0.96862745,
0.96666667, 0.96666667, 0.9627451 , 0.96078431, 0.96078431,
0.9627451 , 0.9627451 , 0.9627451 , 0.96078431]),
'split3_test_score': array([0.90784314, 0.9372549 , 0.9372549 , 0.92941176, 0.92941176,
0.95882353, 0.95882353, 0.96470588, 0.9627451 , 0.9627451 ,
0.98627451, 0.98627451, 0.99215686, 0.99411765, 0.99019608,
0.98823529, 0.98823529, 0.98627451, 0.98431373, 0.98235294,
0.98039216, 0.97647059, 0.97058824, 0.96862745, 0.96862745,
0.97254902, 0.97647059, 0.9745098 , 0.9745098 , 0.97058824,
0.97647059, 0.9745098 , 0.9745098 , 0.97254902, 0.97254902,
0.97058824, 0.96862745, 0.96862745, 0.96862745, 0.96862745,
0.96862745, 0.9745098 , 0.9745098 , 0.97254902, 0.9745098 ,
0.97647059, 0.97647059, 0.97647059, 0.97843137]),
'split4_test_score': array([0.9372549 , 0.9372549 , 0.93333333, 0.92941176, 0.9254902 ,
0.92352941, 0.94901961, 0.94705882, 0.94705882, 0.94705882,
0.94705882, 0.94705882, 0.94705882, 0.94705882, 0.94705882,
0.94705882, 0.97058824, 0.97058824, 0.97647059, 0.97647059,
0.9745098 , 0.9745098 , 0.9745098 , 0.9745098 , 0.9745098 ,
0.9745098 , 0.97254902, 0.9745098 , 0.97254902, 0.97254902,
0.97254902, 0.97254902, 0.97254902, 0.97254902, 0.96862745,
0.96862745, 0.96470588, 0.96470588, 0.96666667, 0.96470588,
0.96666667, 0.96666667, 0.97058824, 0.97058824, 0.96862745,
0.96666667, 0.96666667, 0.96470588, 0.96470588]),
'mean_test_score': array([0.92457516, 0.94481481, 0.95437908, 0.95091503, 0.9516122 ,
0.9611329 , 0.96472767, 0.96662309, 0.968061 , 0.96840959,
0.9735512 , 0.97318083, 0.97947712, 0.98145969, 0.9803268 ,
0.97880174, 0.98422658, 0.98309368, 0.98313725, 0.98309368,
0.98342048, 0.98224401, 0.98028322, 0.97910675, 0.9787146 ,
0.98023965, 0.97949891, 0.97991285, 0.98026144, 0.98065359,
0.98104575, 0.98065359, 0.98028322, 0.9783878 , 0.97723312,
0.9764488 , 0.97675381, 0.9759695 , 0.97636166, 0.97557734,
0.9748366 , 0.97601307, 0.97638344, 0.97559913, 0.97559913,
0.97599129, 0.97599129, 0.97559913, 0.97633987]),
'std_test_score': array([0.03325211, 0.01872544, 0.01660774, 0.0182333 , 0.02064992,
0.02482919, 0.01851883, 0.0182006 , 0.02016003, 0.02108635,
0.02025305, 0.02012114, 0.01809218, 0.01894378, 0.01895695,
0.01887616, 0.01067725, 0.01131942, 0.01120224, 0.01002235,
0.00831217, 0.00860608, 0.00951598, 0.01002235, 0.01015531,
0.00945584, 0.00955541, 0.00828506, 0.01002709, 0.0105113 ,
0.00969438, 0.00990881, 0.01004308, 0.01098385, 0.01175462,
0.01197354, 0.01230688, 0.01254751, 0.0122156 , 0.01273875,
0.01196711, 0.01158181, 0.01253933, 0.01305082, 0.01316813,
0.01298256, 0.01298256, 0.0132844 , 0.01373731]),
'rank_test_score': array([49, 48, 45, 47, 46, 44, 43, 42, 41, 40, 38, 39, 18, 7, 11, 20, 1,
4, 3, 4, 2, 6, 12, 19, 21, 15, 17, 16, 14, 9, 8, 9, 12, 22,
23, 25, 24, 32, 27, 36, 37, 29, 26, 33, 33, 30, 30, 33, 28],
dtype=int32)}
18.1.1.3.4. 用整個 training set 做 fitting.¶
剛剛的 grid_cv 物件,再找完最佳參數後,就已經幫你把整個 training set 給 fit 完了
18.1.1.3.5. 用 testing set 做 predict¶
pred_label_test = grid_cv.predict(X_test)
pred_prob_test = grid_cv.predict_proba(X_test)
18.1.1.3.6. 效果評估¶
# 評估結果
print(grid_cv.score(X_test, y_test))
print(confusion_matrix(y_test, pred_label_test))
print(classification_report(y_test, pred_label_test))
0.9426699426699426
[[31 6]
[ 3 30]]
precision recall f1-score support
democrat 0.91 0.84 0.87 37
republican 0.83 0.91 0.87 33
accuracy 0.87 70
macro avg 0.87 0.87 0.87 70
weighted avg 0.87 0.87 0.87 70
18.1.2. KNN (multi_class)¶
18.1.2.1. 讀資料集¶
要來引入數字辨認資料集
from sklearn import datasets
digits = datasets.load_digits()
這筆資料,x 分成兩種:
images: 1797張image x 8 x 8 的 3d-array.
data: 每張 image 拉成 64 個 column,所以變成 1797x64 的 2d-array
看一下 shape 是不是真的是這樣:
print(digits.images.shape)
print(digits.data.shape)
(1797, 8, 8)
(1797, 64)
我們可以看一張圖片:
plt.imshow(digits.images[1010], cmap=plt.cm.gray_r, interpolation='nearest');
那這個任務,蠻熟悉的,就是給我一張圖片,然後我要辨認出他是 0 ~ 9 的哪個數字
18.1.2.2. fit model & predict¶
# 切資料
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
digits.data,
digits.target,
test_size = 0.2,
random_state = 42,
stratify = digits.target
)
# fit model
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 6)
knn.fit(X_train, y_train)
# 預測 training/testing set
pred_label_train = knn.predict(X_train)
pred_prob_train = knn.predict_proba(X_train)
pred_label_test = knn.predict(X_test)
pred_prob_test = knn.predict_proba(X_test)
# 評估結果
print(knn.score(X_test, y_test))
print(confusion_matrix(y_test, pred_label_test))
print(classification_report(y_test, pred_label_test))
0.9805555555555555
[[36 0 0 0 0 0 0 0 0 0]
[ 0 36 0 0 0 0 0 0 0 0]
[ 0 0 35 0 0 0 0 0 0 0]
[ 0 0 0 37 0 0 0 0 0 0]
[ 0 0 0 0 36 0 0 0 0 0]
[ 0 0 0 0 0 37 0 0 0 0]
[ 0 0 0 0 0 0 35 0 1 0]
[ 0 0 0 0 0 0 0 36 0 0]
[ 0 3 0 0 0 0 0 1 31 0]
[ 0 0 0 0 1 0 0 0 1 34]]
precision recall f1-score support
0 1.00 1.00 1.00 36
1 0.92 1.00 0.96 36
2 1.00 1.00 1.00 35
3 1.00 1.00 1.00 37
4 0.97 1.00 0.99 36
5 1.00 1.00 1.00 37
6 1.00 0.97 0.99 36
7 0.97 1.00 0.99 36
8 0.94 0.89 0.91 35
9 1.00 0.94 0.97 36
accuracy 0.98 360
macro avg 0.98 0.98 0.98 360
weighted avg 0.98 0.98 0.98 360
18.1.2.3. overfitting exploration¶
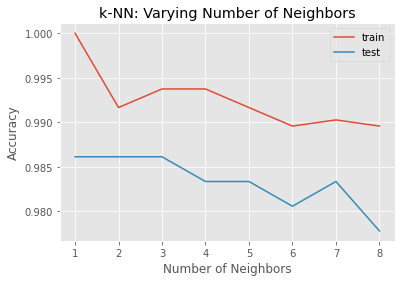
最後,我們來玩點新的,看看 overfitting 的狀況
neighbors = np.arange(1, 9) # knn的 k,從複雜(1)到簡單(9)
train_accuracy = np.empty(len(neighbors)) # 先擺個 placeholder
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(X_train, y_train)
train_accuracy[i] = knn.score(X_train, y_train)
test_accuracy[i] = knn.score(X_test, y_test)
畫個圖看看
fig, ax = plt.subplots()
ax.plot(neighbors, train_accuracy, label = "train");
ax.plot(neighbors, test_accuracy, label = "test");
ax.legend();
ax.set(
xlabel='Number of Neighbors',
ylabel='Accuracy',
title='k-NN: Varying Number of Neighbors'
);
18.1.3. Logistic (binary)¶
18.1.3.1. 讀資料集¶
diabetes = pd.read_csv("data/diabetes.csv")
diabetes
| pregnancies | glucose | diastolic | triceps | insulin | bmi | dpf | age | diabetes | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 763 | 10 | 101 | 76 | 48 | 180 | 32.9 | 0.171 | 63 | 0 |
| 764 | 2 | 122 | 70 | 27 | 0 | 36.8 | 0.340 | 27 | 0 |
| 765 | 5 | 121 | 72 | 23 | 112 | 26.2 | 0.245 | 30 | 0 |
| 766 | 1 | 126 | 60 | 0 | 0 | 30.1 | 0.349 | 47 | 1 |
| 767 | 1 | 93 | 70 | 31 | 0 | 30.4 | 0.315 | 23 | 0 |
768 rows × 9 columns
diabetes.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pregnancies 768 non-null int64
1 glucose 768 non-null int64
2 diastolic 768 non-null int64
3 triceps 768 non-null int64
4 insulin 768 non-null int64
5 bmi 768 non-null float64
6 dpf 768 non-null float64
7 age 768 non-null int64
8 diabetes 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
18.1.3.2. fit, predict, and evaluate¶
# 切資料
from sklearn.model_selection import train_test_split
# preprocess (沒用到)
# from sklearn.impute import SimpleImputer
# from sklearn.pipeline import Pipeline
# modeling
from sklearn.linear_model import LogisticRegression
# hyper-parameter tunning
from sklearn.model_selection import GridSearchCV
# evaluation
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score
# 切資料
X = diabetes.drop("diabetes", axis = 1)
y = diabetes["diabetes"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = 0.4,
random_state = 42,
stratify = y
)
# model
logreg = LogisticRegression()
# hyper-parameter tunning
# logistic regression 的 regularization parameter 是 C ,代表 inverse of the regularization strength,
# 所以,C 越大,regularize能力越爛,越容易 overfit model;
# C 越小,regularize能力越強,越容易 underfit model
c_space = np.logspace(-5, 8, 15)
param_grid = {"C": c_space, "penalty": ['l1', 'l2']}
logreg_cv = GridSearchCV(logreg, param_grid, cv=5)
logreg_cv.fit(X_train, y_train)
print("Tuned Logistic Regression Parameters: {}".format(logreg_cv.best_params_))
print("Best score is {}".format(logreg_cv.best_score_))
# 預測 training/testing set
y_pred = logreg_cv.predict(X_test)
y_pred_prob = logreg_cv.predict_proba(X_test)[:,1]
# 評估結果
print("AUC: {}".format(roc_auc_score(y_test, y_pred_prob)))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
plt.plot([0,1],[0, 1], "k--")
plt.plot(fpr, tpr, label = "Logistic Regression")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Logistic Regression ROC Curve")
plt.show()
print(roc_auc_score(y_test, y_pred))
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/model_selection/_validation.py:372: FitFailedWarning:
75 fits failed out of a total of 150.
The score on these train-test partitions for these parameters will be set to nan.
If these failures are not expected, you can try to debug them by setting error_score='raise'.
Below are more details about the failures:
--------------------------------------------------------------------------------
75 fits failed with the following error:
Traceback (most recent call last):
File "/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/model_selection/_validation.py", line 680, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py", line 1461, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py", line 447, in _check_solver
raise ValueError(
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn(some_fits_failed_message, FitFailedWarning)
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/model_selection/_search.py:969: UserWarning: One or more of the test scores are non-finite: [ nan 0.72391304 nan 0.7673913 nan 0.77608696
nan 0.7826087 nan 0.77391304 nan 0.78913043
nan 0.78043478 nan 0.78043478 nan 0.77391304
nan 0.77391304 nan 0.76956522 nan 0.77391304
nan 0.7673913 nan 0.77608696 nan 0.77391304]
warnings.warn(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Tuned Logistic Regression Parameters: {'C': 0.4393970560760795, 'penalty': 'l2'}
Best score is 0.7891304347826086
[[169 32]
[ 47 60]]
precision recall f1-score support
0 0.78 0.84 0.81 201
1 0.65 0.56 0.60 107
accuracy 0.74 308
macro avg 0.72 0.70 0.71 308
weighted avg 0.74 0.74 0.74 308
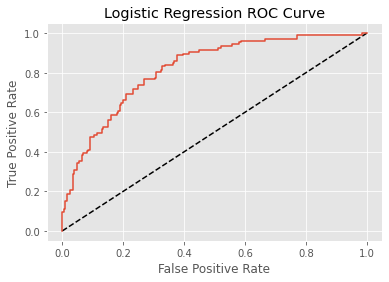
0.7007718417259498
precision & recall
precision = 你說是 positive 的人中,有多少個是真的 positive
recall = true positive rate = 真的是positive的人中,你揪出了幾個?
cutpoint -> 1, precision ->1,因為惜字如金,只要我說是positive,幾乎一定是 positive。
cutpoint -> 0, recall -> 1, 因為cutpoint接近0的時候,幾乎所有人全被說 positive,那recall的分子就幾乎全中了
18.1.4. DecisionTree (binary)¶
# 切資料
from sklearn.model_selection import train_test_split
# preprocess (沒用到)
# from sklearn.impute import SimpleImputer
# from sklearn.pipeline import Pipeline
# modeling
from sklearn.tree import DecisionTreeClassifier
# hyper-parameter tunning
from sklearn.model_selection import RandomizedSearchCV
# evaluation
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score
# utils
from scipy.stats import randint
# 讀檔 & 切資料
diabetes = pd.read_csv("data/diabetes.csv")
X = diabetes.drop("diabetes", axis = 1)
y = diabetes["diabetes"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = 0.4,
random_state = 42,
stratify = y
)
# model
tree = DecisionTreeClassifier()
# hyper-parameter tunning
param_dist = {"max_depth": [3, None],
"max_features": randint(1, 9),
"min_samples_leaf": randint(1, 9),
"criterion": ["gini", "entropy"]}
tree_randomcv = RandomizedSearchCV(tree, param_dist, cv=5)
tree_randomcv.fit(X_train, y_train)
print("Tuned Decision Tree Parameters: {}".format(tree_randomcv.best_params_))
print("Best score is {}".format(tree_randomcv.best_score_))
# 預測 training/testing set
y_pred = tree_randomcv.predict(X_test)
y_pred_prob = tree_randomcv.predict_proba(X_test)[:,1]
# 評估結果
print("AUC: {}".format(roc_auc_score(y_test, y_pred_prob)))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
plt.plot([0,1],[0, 1], "k--")
plt.plot(fpr, tpr, label = "Decision Tree")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Logistic Regression ROC Curve")
plt.show()
Tuned Decision Tree Parameters: {'criterion': 'entropy', 'max_depth': 3, 'max_features': 5, 'min_samples_leaf': 5}
Best score is 0.7608695652173914
AUC: 0.7851629701957501
[[174 27]
[ 57 50]]
precision recall f1-score support
0 0.75 0.87 0.81 201
1 0.65 0.47 0.54 107
accuracy 0.73 308
macro avg 0.70 0.67 0.67 308
weighted avg 0.72 0.73 0.71 308
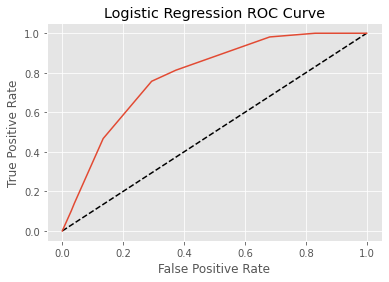
18.1.5. SVC (binary)¶
# Import necessary modules
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# 讀資料
vote_raw = pd.read_csv("data/house-votes-84.csv")
vote = vote_raw.copy()
col_names = ['party', 'infants', 'water', 'budget', 'physician', 'salvador',
'religious', 'satellite', 'aid', 'missile', 'immigration', 'synfuels',
'education', 'superfund', 'crime', 'duty_free_exports', 'eaa_rsa']
vote.columns = col_names
vote[vote == "?"] = np.nan # 把 ? 改成 na
for i in col_names[1:]:
vote[i] = vote[i].replace({"y": 1, "n": 0})
X = vote.drop("party", axis = 1)
y = vote["party"]
# 切資料
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# pipeline: 前處理 & model
steps = [('imputation', SimpleImputer(missing_values=np.nan, strategy='most_frequent')),
("scaler", StandardScaler()),
('SVM', SVC())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# hyper-parameter tunning
parameters = {'SVM__C':[1, 10, 100],
'SVM__gamma':[0.1, 0.01]}
cv = GridSearchCV(pipeline, parameters, cv = 3)
cv.fit(X_train, y_train)
print("Tuned Model Parameters: {}".format(cv.best_params_))
# 預測
y_pred = cv.predict(X_test)
# performance
print("Accuracy: {}".format(cv.score(X_test, y_test)))
print(classification_report(y_test, y_pred))
Tuned Model Parameters: {'SVM__C': 10, 'SVM__gamma': 0.01}
Accuracy: 0.9541984732824428
precision recall f1-score support
democrat 0.99 0.94 0.96 83
republican 0.90 0.98 0.94 48
accuracy 0.95 131
macro avg 0.95 0.96 0.95 131
weighted avg 0.96 0.95 0.95 131
18.2. Regression¶
18.2.1. Gapminder Data¶
import pandas as pd
gapminder = pd.read_csv("data/gm_2008_region.csv")
gapminder.head()
| population | fertility | HIV | CO2 | BMI_male | GDP | BMI_female | life | child_mortality | Region | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 34811059.0 | 2.73 | 0.1 | 3.328945 | 24.59620 | 12314.0 | 129.9049 | 75.3 | 29.5 | Middle East & North Africa |
| 1 | 19842251.0 | 6.43 | 2.0 | 1.474353 | 22.25083 | 7103.0 | 130.1247 | 58.3 | 192.0 | Sub-Saharan Africa |
| 2 | 40381860.0 | 2.24 | 0.5 | 4.785170 | 27.50170 | 14646.0 | 118.8915 | 75.5 | 15.4 | America |
| 3 | 2975029.0 | 1.40 | 0.1 | 1.804106 | 25.35542 | 7383.0 | 132.8108 | 72.5 | 20.0 | Europe & Central Asia |
| 4 | 21370348.0 | 1.96 | 0.1 | 18.016313 | 27.56373 | 41312.0 | 117.3755 | 81.5 | 5.2 | East Asia & Pacific |
gapminder.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 139 entries, 0 to 138
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 population 139 non-null float64
1 fertility 139 non-null float64
2 HIV 139 non-null float64
3 CO2 139 non-null float64
4 BMI_male 139 non-null float64
5 GDP 139 non-null float64
6 BMI_female 139 non-null float64
7 life 139 non-null float64
8 child_mortality 139 non-null float64
9 Region 139 non-null object
dtypes: float64(9), object(1)
memory usage: 11.0+ KB
18.2.2. Linear Regression¶
18.2.2.1. train/test¶
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# preprocess.
# gapminder_onehot = pd.get_dummies(gapminder)
gapminder_dummy = pd.get_dummies(gapminder, drop_first = True)
# 分割資料
X = gapminder_dummy.drop("life", axis = 1)
y = gapminder_dummy["life"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=42)
# fit model
reg_all = LinearRegression()
reg_all.fit(X_train, y_train)
# Predict on the test data: y_pred
y_pred = reg_all.predict(X_test)
# Compute and print R^2 and RMSE
print("R^2: {}".format(reg_all.score(X_test, y_test)))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error: {}".format(rmse))
R^2: 0.8219419939587727
Root Mean Squared Error: 3.405248115733344
18.2.2.2. CV¶
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# 分割資料
# 不分割了,因為等等直接用 cv
# fit model
reg = LinearRegression()
cv_scores = cross_val_score(reg, X, y, cv = 5)
print(cv_scores) # 5-fold cv 結果
print(f"Average 5-Fold CV Score: {str(np.mean(cv_scores))}")
[0.8196741 0.80301541 0.89758712 0.80425614 0.94015848]
Average 5-Fold CV Score: 0.8529382494240787
18.2.3. Lasso Regression¶
# Import Lasso
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# pipeline
lasso_pipe = make_pipeline(
StandardScaler(),
Lasso(alpha = 0.4)
)
# Fit the regressor to the data
lasso_pipe.fit(X_train, y_train)
y_pred = lasso_pipe.predict(X_test)
# Compute and print R^2 and RMSE
print("R^2: {}".format(lasso_pipe.score(X_test, y_test)))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error: {}".format(rmse))
R^2: 0.8401265152705228
Root Mean Squared Error: 3.2266824659707334
看一下哪些變數被 shrinkage 到 0 ,哪些變數最重要:
# Compute and print the coefficients
lasso_coef = lasso_pipe.named_steps["lasso"].coef_
print(lasso_coef)
# Plot the coefficients
plt.plot(range(len(X_train.columns)), lasso_coef)
plt.xticks(range(len(X_train.columns)), X_train.columns.values, rotation=60)
plt.margins(0.02)
[-0. -0.08591553 -2.91968634 -0. 0.58693244 1.6922106
-1.11083667 -4.3362549 -0.48746711 0. 0. 0.
-0.1705074 ]
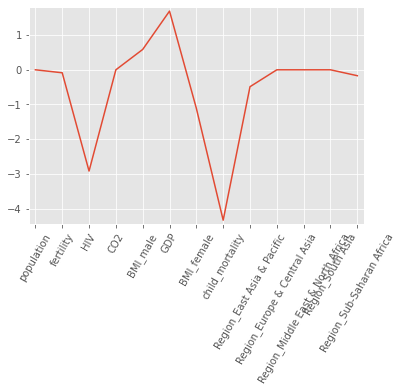
18.2.4. Ridge Regression¶
def display_plot(cv_scores, cv_scores_std):
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(alpha_space, cv_scores)
std_error = cv_scores_std / np.sqrt(10)
ax.fill_between(alpha_space, cv_scores + std_error, cv_scores - std_error, alpha=0.2)
ax.set_ylabel('CV Score +/- Std Error')
ax.set_xlabel('Alpha')
ax.axhline(np.max(cv_scores), linestyle='--', color='.5')
ax.set_xlim([alpha_space[0], alpha_space[-1]])
ax.set_xscale('log')
plt.show()
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# ridge = Ridge(normalize=True)
# Compute scores over range of alphas
for alpha in alpha_space:
# Specify the alpha value to use: ridge.alpha
ridge = make_pipeline(
StandardScaler(),
Ridge(alpha = alpha)
)
# ridge.named_steps["ridge"].alpha = alpha
#ridge.alpha = alpha
# Perform 10-fold CV: ridge_cv_scores
ridge_cv_scores = cross_val_score(ridge, X, y, cv=10)
# Append the mean of ridge_cv_scores to ridge_scores
ridge_scores.append(np.mean(ridge_cv_scores))
# Append the std of ridge_cv_scores to ridge_scores_std
ridge_scores_std.append(np.std(ridge_cv_scores))
# Display the plot
display_plot(ridge_scores, ridge_scores_std)
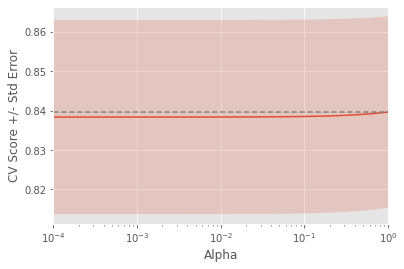
18.2.5. Elastic net¶
# Import necessary modules
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error
# 讀資料 & 切資料
gapminder = pd.read_csv("data/gm_2008_region.csv")
X = gapminder_dummy.drop("life", axis = 1)
y = gapminder_dummy["life"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 42)
# pipeline: 前處理 & model
steps = [('imputation', SimpleImputer(missing_values=np.nan, strategy='mean')),
("scaler", StandardScaler()),
("elasticnet", ElasticNet())]
pipeline = Pipeline(steps)
# hyper-parameter tunning
parameters = {"elasticnet__l1_ratio":np.linspace(0,1,30)} # l1_ratio*L1_loss + (1-l1_ratio)*L2_loss
gm_cv = GridSearchCV(pipeline, parameters, cv = 5)
gm_cv.fit(X_train, y_train)
print("Tuned ElasticNet l1 ratio: {}".format(gm_cv.best_params_))
# Predict
y_pred = gm_cv.predict(X_test)
# performance
r2 = gm_cv.score(X_test, y_test)
mse = mean_squared_error(y_test, y_pred)
print("Tuned ElasticNet R squared: {}".format(r2))
print("Tuned ElasticNet MSE: {}".format(mse))
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 8.126e+02, tolerance: 5.589e-01 Linear regression models with null weight for the l1 regularization term are more efficiently fitted using one of the solvers implemented in sklearn.linear_model.Ridge/RidgeCV instead.
model = cd_fast.enet_coordinate_descent(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 8.410e+02, tolerance: 5.893e-01 Linear regression models with null weight for the l1 regularization term are more efficiently fitted using one of the solvers implemented in sklearn.linear_model.Ridge/RidgeCV instead.
model = cd_fast.enet_coordinate_descent(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 7.983e+02, tolerance: 5.890e-01 Linear regression models with null weight for the l1 regularization term are more efficiently fitted using one of the solvers implemented in sklearn.linear_model.Ridge/RidgeCV instead.
model = cd_fast.enet_coordinate_descent(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 8.506e+02, tolerance: 5.814e-01 Linear regression models with null weight for the l1 regularization term are more efficiently fitted using one of the solvers implemented in sklearn.linear_model.Ridge/RidgeCV instead.
model = cd_fast.enet_coordinate_descent(
/Volumes/GoogleDrive/我的雲端硬碟/0. codepool_python/python_ds/python_ds_env/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 8.375e+02, tolerance: 5.802e-01 Linear regression models with null weight for the l1 regularization term are more efficiently fitted using one of the solvers implemented in sklearn.linear_model.Ridge/RidgeCV instead.
model = cd_fast.enet_coordinate_descent(
Tuned ElasticNet l1 ratio: {'elasticnet__l1_ratio': 1.0}
Tuned ElasticNet R squared: 0.8862016549771035
Tuned ElasticNet MSE: 8.594868215979249